
데이터 셋
미국 의회 입법가 데이터셋을 사용한다.
첫 번째 term
여러번 임기한 사람들이 있다.
1
2
3
SELECT id_bioguide, COUNT(*)
FROM legislators_terms
GROUP BY id_bioguide;
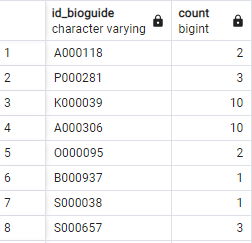
- 아이디별로 가장 처음 임기했던 기간을 조회한다.
- 아이디별로 여러번 임기한 사람들이 있기 때문에 가장 처음 임기를 시작한 날짜를 계산한 것이다.
1 2 3
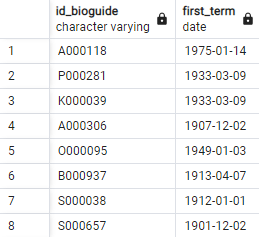
SELECT id_bioguide, MIN(term_start) AS first_term FROM legislators_terms GROUP BY id_bioguide;
![]()
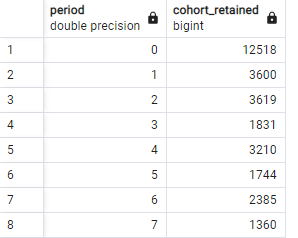
Period 계산하기
- 위 쿼리를 FROM절에 서브쿼리로 사용한다.
- ID를 기준으로 JOIN한다. A 테이블 : 12518 rows (중복 제거) B 테이블 : 44063 rows (중복 제거되지 않음)
- 처음 임기 시작 날짜와 이후 모든 임기 날짜에 대해 차이를 구한 후 연도만을 조회한다. (Period)
- COUNT() 함수를 사용하여 개수를 계산한다.
1 2 3 4 5 6 7 8 9 10
SELECT DATE_PART('year', AGE(B.term_start, A.first_term)) AS period, COUNT(DISTINCT(A.id_bioguide)) AS cohort_retained FROM( SELECT id_bioguide, MIN(term_start) AS first_term FROM legislators_terms GROUP BY id_bioguide ) AS A JOIN legislators_terms AS B ON A.id_bioguide = B.id_bioguide GROUP BY DATE_PART('year', AGE(B.term_start, A.first_term))
![]()
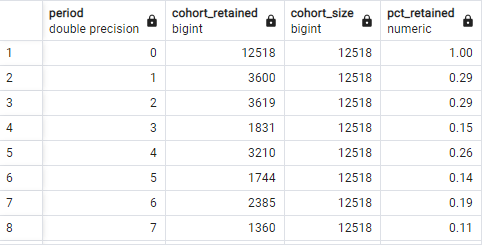
첫 번째 기간(period=0)에 대한 비율
- 위 쿼리를 FROM절의 서브쿼리로 사용한다.
- 앞서 계산한 period와 cohort_retained을 활용한다.
- period를 오름차순으로 정렬하였을 때, 맨 처음 오는 cohort_retained 값을 담은 컬럼을 생성한다.
- cohort_retained를 위 컬럼으로 나누어 비율을 계산한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
SELECT period, cohort_retained, FIRST_VALUE(cohort_retained) OVER(ORDER BY period) AS cohort_size, ROUND(cohort_retained * 1.0 / FIRST_VALUE(cohort_retained) OVER(ORDER BY period), 2) AS pct_retained FROM( SELECT DATE_PART('year', AGE(B.term_start, A.first_term)) AS period, COUNT(DISTINCT(A.id_bioguide)) AS cohort_retained FROM( SELECT id_bioguide, MIN(term_start) AS first_term FROM legislators_terms GROUP BY id_bioguide ) AS A JOIN legislators_terms AS B ON A.id_bioguide = B.id_bioguide GROUP BY DATE_PART('year', AGE(B.term_start, A.first_term)) ) AS sub;
![]()
period를 컬럼으로 만들기
- 위 쿼리를 FROM절의 서브쿼리로 이용한다.
- 그러나 3회 중첩하여 서브쿼리를 사용하기에 너무 복잡해 보일 것 같아서 WITH를 사용하겠다.
- GROUP BY절에 cohort_size를 사용했기 때문에 12518 값을 가진 하나의 행으로 나타나게 된다.
- CASE WHEN 구문을 사용하여 각 기간에 해당하는 비율 컬럼을 생성한다. ```sql WITH result AS ( SELECT period, cohort_retained, FIRST_VALUE(cohort_retained) OVER(ORDER BY period) AS cohort_size, ROUND(cohort_retained * 1.0 / FIRST_VALUE(cohort_retained) OVER(ORDER BY period), 2) AS pct_retained FROM( SELECT DATE_PART(‘year’, AGE(B.term_start, A.first_term)) AS period, COUNT(DISTINCT(A.id_bioguide)) AS cohort_retained FROM( SELECT id_bioguide, MIN(term_start) AS first_term FROM legislators_terms GROUP BY id_bioguide ) AS A JOIN legislators_terms AS B ON A.id_bioguide = B.id_bioguide GROUP BY DATE_PART(‘year’, AGE(B.term_start, A.first_term)) ) AS sub )
SELECT cohort_size, MAX(CASE WHEN period=0 THEN pct_retained END) AS yr0, MAX(CASE WHEN period=1 THEN pct_retained END) AS yr1, MAX(CASE WHEN period=2 THEN pct_retained END) AS yr2, MAX(CASE WHEN period=3 THEN pct_retained END) AS yr3, MAX(CASE WHEN period=4 THEN pct_retained END) AS yr4 FROM result GROUP BY cohort_size; ``` 