
누적 계산
- id별로 term sart를 오름차순 했을 때 첫 번째 term type값
- id별로 가장 작은 term start 날짜
- id별로 가장 작은 term start 날짜 + 10년
- legislators_term 테이블 JOIN
- B 테이블의 term start가 A 테이블의 first term과 10년 후 사이에 있는 날짜
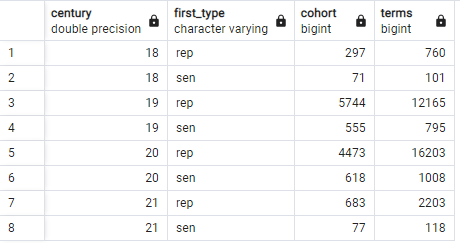
- century, first type별 그루핑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
SELECT DATE_PART('century', A.first_term) AS century, first_type, COUNT(DISTINCT A.id_bioguide) AS cohort, COUNT(B.term_start) AS terms FROM ( SELECT DISTINCT id_bioguide, FIRST_VALUE(term_type) OVER(PARTITION BY id_bioguide ORDER BY term_start ASC) AS first_type, MIN(term_start) OVER(PARTITION BY id_bioguide) AS first_term, MIN(term_start) OVER(PARTITION BY id_bioguide) + INTERVAL '10 years' AS first_plus_10 FROM legislators_terms ) AS A LEFT JOIN legislators_terms AS B ON A.id_bioguide = B.id_bioguide AND B.term_start BETWEEN A.first_term AND A.first_plus_10 GROUP BY 1, 2;
![]()
- id 개수로 나누어 평균 계산
- CASE 구문을 이용해 피봇
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
SELECT century, MAX(CASE WHEN first_type = 'rep' THEN cohort END) AS rep_cohort, MAX(CASE WHEN first_type = 'rep' THEN terms_per_leg END) AS avg_rep_terms, MAX(CASE WHEN first_type = 'sen' THEN cohort END) AS sen_cohort, MAX(CASE WHEN first_type = 'sen' THEN terms_per_leg END) AS avg_sen_terms FROM ( SELECT DATE_PART('century', A.first_term) AS century, first_type, COUNT(DISTINCT A.id_bioguide) AS cohort, COUNT(B.term_start) AS terms, ROUND(COUNT(B.term_start) * 1.0 / COUNT(DISTINCT A.id_bioguide), 3) AS terms_per_leg FROM ( SELECT DISTINCT id_bioguide, FIRST_VALUE(term_type) OVER(PARTITION BY id_bioguide ORDER BY term_start ASC) AS first_type, MIN(term_start) OVER(PARTITION BY id_bioguide) AS first_term, MIN(term_start) OVER(PARTITION BY id_bioguide) + INTERVAL '10 years' AS first_plus_10 FROM legislators_terms ) AS A LEFT JOIN legislators_terms AS B ON A.id_bioguide = B.id_bioguide AND B.term_start BETWEEN A.first_term AND A.first_plus_10 GROUP BY 1, 2 ) AS result GROUP BY 1
![]()
