
CNN 모델의 발전
- 1998: LeNet – Gradient-based Learning Applied to Document Recognition
- 2012: AlexNet – ImageNet Classification with Deep Convolutional Neural Network
- 2014: VggNet – Very Deep Convolutional Networks for Large-Scale Image Recognition
- 2014: GooLeNet – Going Deeper with Convolutions
- 2014: SppNet – Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 2015: ResNet – Deep Residual Learning for Image Recognition
- 2016: Xception – Xception: Deep Learning with Depthwise Separable Convolutions
- 2017: MobileNet – MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- 2017: DenseNet – Densely Connected Convolutional Networks
- 2017: SeNet – Squeeze and Excitation Networks
- 2017: ShuffleNet – ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- 2018: NasNet – Learning Transferable Architectures for Scalable Image Recognition
- 2018: Bag of Tricks – Bag of Tricks for Image Classification with Convolutional Neural Networks
- 2019: EfficientNet – EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
VGGNet(Visual Geometry Group Net)
2014년 ILSVRC에서 2등 차지 (상위-5 오류율: 7.32%), 이 후의 수많은 연구에 영향을 미침
- 특징
- 활성화 함수로
ReLU사용, Dropout 적용 - 합성곱과 풀링 계층으로 구성된 블록과 분류를 위한 완전 연결계층으로 결합된 전형적인 구조
- 이미지 변환, 좌우 반전 등의 변환을 시도하여 인위적으로 데이터셋을 늘림
- 몇 개의 합성곱 계층과 최대-풀링 계층이 따르는 5개의 블록과, 3개의 완전연결계층(학습 시, 드롭아웃 사용)으로 구성
- 모든 합성곱과 최대-풀링 계층에
padding='SAME'적용 - 합성곱 계층에는
stride=1, 활성화 함수로ReLU사용 - 특징 맵 깊이를 증가시킴
- 척도 변경을 통한 데이터 보강(Data Augmentation)
- 활성화 함수로
기여
- 3x3 커널을 갖는 두 합성곱 계층을 쌓은 스택이 5x5 커널을 갖는 하나의 합성곱 계층과 동일한 수용영역(ERF)을 가짐
- 11x11 사이즈의 필터 크기를 가지는 AlexNet과 비교하여, 더 작은 합성곱 계층을 더 많이 포함해 더 큰 ERF를 얻음
- 합성곱 계층의 개수가 많아지면, 매개변수 개수를 줄이고, 비선형성을 증가시킴
- VGG-16 모델(16개 층)
- VGG-19 모델(19개 층)
- ImageNet에서 훈련이 끝난 후 얻게된 매개변수 값 로딩
- 네트워크를 다시 처음부터 학습하고자 한다면
weights=None으로 설정, 케라스에서 무작위로 가중치를 설정함 include_top=False: VGG의 밀집 계층을 제외한다는 뜻- 해당 네트워크의 출력은 합성곱/최대-풀링 블록의 특징맵이 됨
pooling: 특징맵을 반환하기 전에 적용할 선택적인 연산을 지정
1
2
3
4
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg19 import VGG19, preprocess_input, decode_predictions
1
2
3
4
5
6
# weight은 imagenet에서 사용한 가중치를 사용
# 실제 가중치가 적용된 model을 다운로드
vggnet= VGG19(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
vggnet.summary()
1
2
# 웹에 있는 사진 다운
!wget -O dog.jpg https://www.publicdomainpictures.net/pictures/250000/nahled/dog-beagle-portrait.jpg
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
--2023-03-09 14:20:19-- https://www.publicdomainpictures.net/pictures/250000/nahled/dog-beagle-portrait.jpg
Resolving www.publicdomainpictures.net (www.publicdomainpictures.net)... 104.20.44.162, 104.20.45.162, 172.67.2.204, ...
Connecting to www.publicdomainpictures.net (www.publicdomainpictures.net)|104.20.44.162|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 94395 (92K) [image/jpeg]
Saving to: ‘dog.jpg’
dog.jpg 100%[===================>] 92.18K --.-KB/s in 0.003s
2023-03-09 14:20:20 (29.1 MB/s) - ‘dog.jpg’ saved [94395/94395]
```python
# 다운로드한 dog.jpg를 terget_size로 줄여줌
# dog의 input은 [(None, 224, 224, 3)] 크기를 가짐
img = image.load_img('dog.jpg', target_size=(224, 224))
plt.imshow(img)
# 이미지를 array 형태로 변환(학습할 모델의 입력으로 사용하기 위해)
x = image.img_to_array(img)
# 기존 모형에 batch_size=1 추가
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
# 예측
preds = vggnet.predict(x)
# 예측 결과 decode_predictions을 통해 반환
print(decode_predictions(preds))
1
2
1/1 [==============================] - 0s 28ms/step
[[('n02088364', 'beagle', 0.83961403), ('n02089973', 'English_foxhound', 0.08818262), ('n02089867', 'Walker_hound', 0.062327106), ('n02088238', 'basset', 0.004562265), ('n02088632', 'bluetick', 0.0033385658)]]
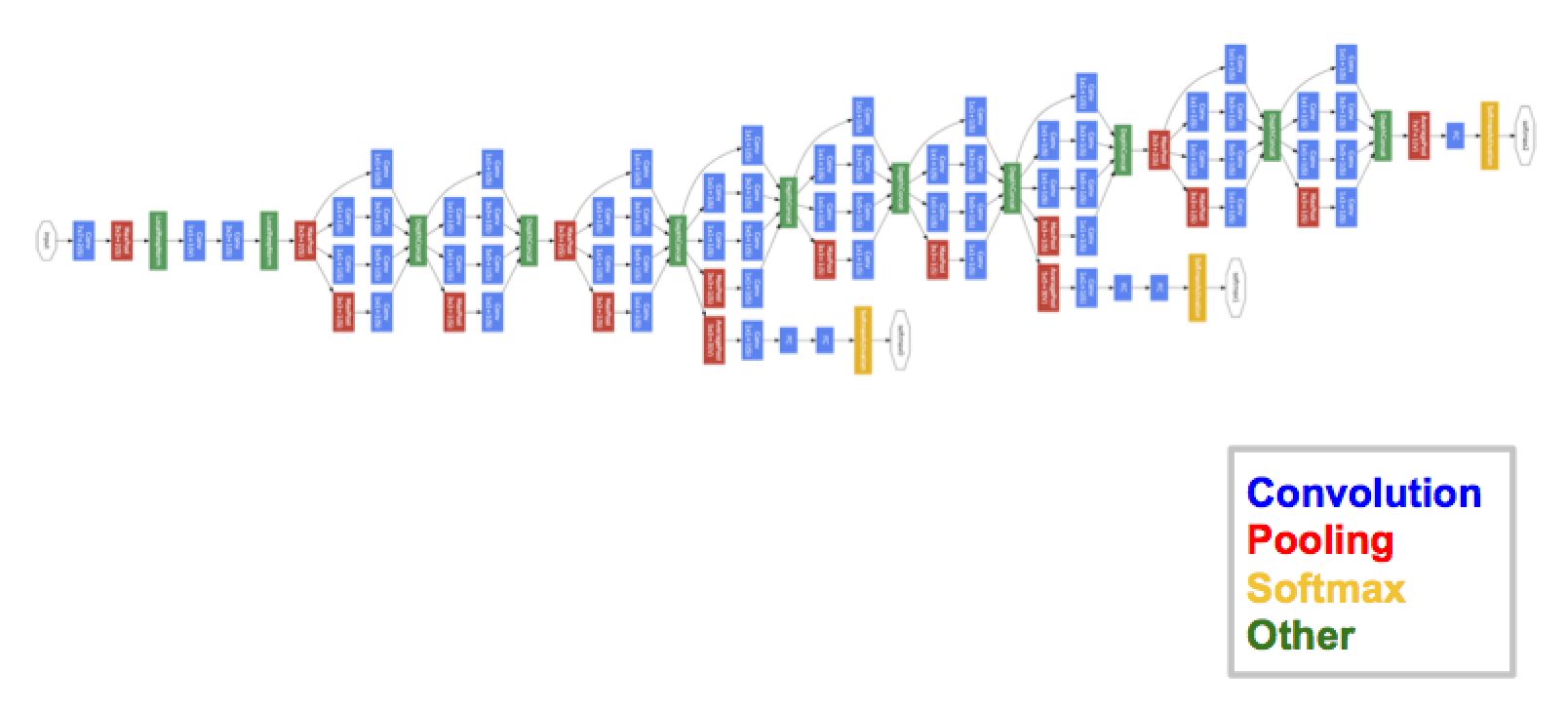
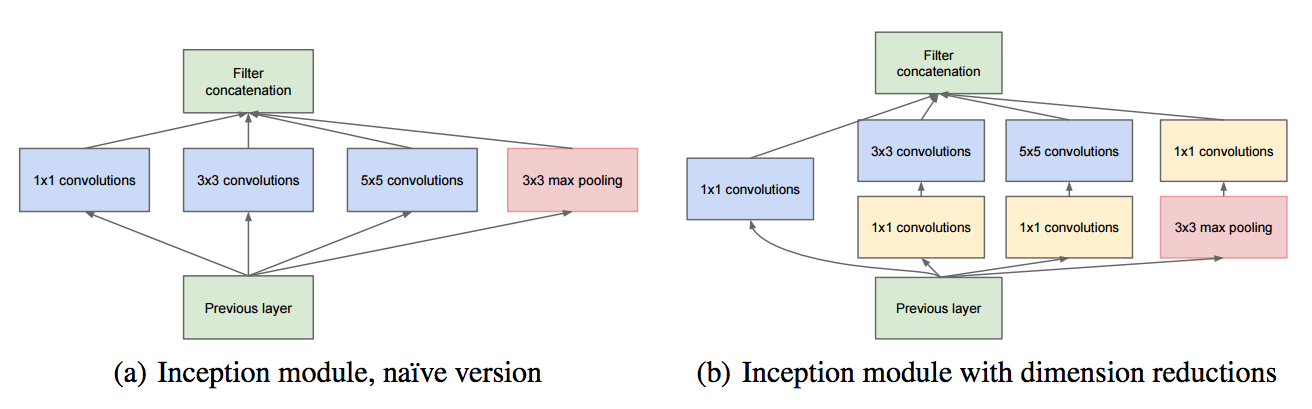
## GoogLeNet, Inception
- VGGNet을 제치고 같은 해 분류 과제에서 1등을 차지
인셉션 블록이라는 개념을 도입하여, 인셉션 네트워크(Inception Network)라고도 불림
![]()
- 특징
- CNN 계산 용량을 최적화하는 것을 고려
- 전형적인 합성곱, 풀링 계층으로 시작하고, 이 정보는 9개의 인셉션 모듈 스택을 통과 (해당 모듈을 하위 네트워크라고도 함)
- 각 모듈에서 입력 특징 맵은 서로 다른 계층으로 구성된 4개의 병렬 하위 블록에 전달되고, 이를 서로 다시 연결
- 모든 합성곱과 풀링 계층의
padding옵션은'SAME'이며stride=1활성화 함수는ReLU사용
- 기여
- 규모가 큰 블록과 병목을 보편화
- 병목 계층으로 1x1 합성곱 계층 사용
- 완전 연결 계층 대신 풀링 계층 사용
- 중간 소실로 경사 소실 문제 해결
![]()
1
from tensorflow.keras.applications.inception_v3 import InceptionV3, preprocess_input, decode_predictions
1
2
3
4
5
6
# include_top=True : top 부분 가져오기
# weights='imagenet' : imgnet의 가중치 그대로 사용
inception = InceptionV3(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
inception.summary()
1
!wget -O fish.jpg https://upload.wikimedia.org/wikipedia/commons/7/7a/Goldfish_1.jpg
1
2
3
4
5
6
7
8
9
10
--2023-03-09 14:37:13-- https://upload.wikimedia.org/wikipedia/commons/7/7a/Goldfish_1.jpg
Resolving upload.wikimedia.org (upload.wikimedia.org)... 103.102.166.240, 2001:df2:e500:ed1a::2:b
Connecting to upload.wikimedia.org (upload.wikimedia.org)|103.102.166.240|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 4648040 (4.4M) [image/jpeg]
Saving to: ‘fish.jpg’
fish.jpg 100%[===================>] 4.43M 2.86MB/s in 1.5s
2023-03-09 14:37:16 (2.86 MB/s) - ‘fish.jpg’ saved [4648040/4648040]
1
2
3
4
5
6
7
8
9
10
11
12
13
# 다운로드한 fish.jpg를 terget_size로 줄여줌
# fish의 input은 [(None, 299, 299, 3 0)] 크기를 가짐
img = image.load_img('fish.jpg', target_size=(299, 299))
plt.imshow(img)
# 이미지를 array 형태로 변환(학습할 모델의 입력으로 사용하기 위해)
x = image.img_to_array(img)
# 기존 모형에 batch_size=1 추가
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
# 예측
preds = inception.predict(x)
# 예측 결과 decode_predictions을 통해 반환
print(decode_predictions(preds))
1
2
1/1 [==============================] - 2s 2s/step
[[('n01443537', 'goldfish', 0.9748526), ('n02701002', 'ambulance', 0.0023246657), ('n02606052', 'rock_beauty', 0.0019062766), ('n02607072', 'anemone_fish', 0.0006647558), ('n09256479', 'coral_reef', 0.0004319898)]]
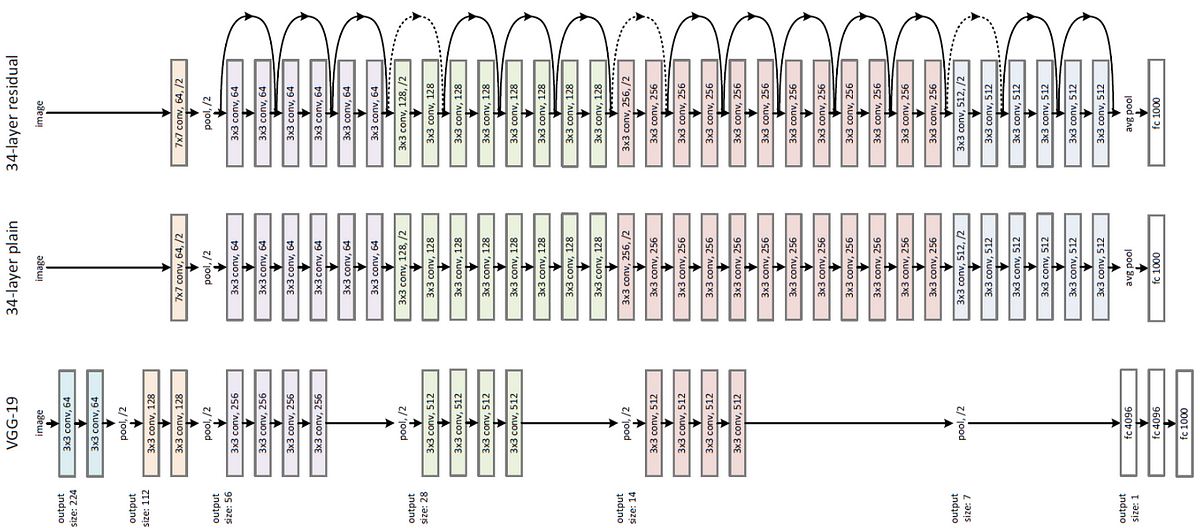
## ResNet(Residual Net)
- 네트워크의 깊이가 깊어질수록 경사가 소실되거나 폭발하는 문제를 해결하고자 함
- 병목 합성곱 계층을 추가하거나 크기가 작은 커널을 사용
- 152개의 훈련가능한 계층을 수직으로 연결하여 구성
- 모든 합성곱과 풀링 계층에서 패딩옵셥으로
'SAME',stride=1사용 3x3 합성곱 계층 다음마다 배치 정규화 적용, 1x1 합성곱 계층에는 활성화 함수가 존재하지 않음
![]()
1
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
1
2
3
4
resnet = ResNet50(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
resnet.summary()
1
!wget -O bee.jog https://upload.wikimedia.org/wikipedia/commons/4/4d/Apis_mellifera_Western_honey_bee.jpg
1
2
3
4
5
6
7
8
9
10
--2023-03-09 14:46:48-- https://upload.wikimedia.org/wikipedia/commons/4/4d/Apis_mellifera_Western_honey_bee.jpg
Resolving upload.wikimedia.org (upload.wikimedia.org)... 103.102.166.240, 2620:0:862:ed1a::2:b
Connecting to upload.wikimedia.org (upload.wikimedia.org)|103.102.166.240|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 2421052 (2.3M) [image/jpeg]
Saving to: ‘bee.jog’
bee.jog 100%[===================>] 2.31M --.-KB/s in 0.08s
2023-03-09 14:46:48 (29.2 MB/s) - ‘bee.jog’ saved [2421052/2421052]
1
2
3
4
5
6
7
8
9
10
11
12
13
# 다운로드한 bee.jpg를 terget_size로 줄여줌
# bee의 input은 [(None, 224, 224, 3 0)] 크기를 가짐
img = image.load_img('bee.jog', target_size=(224, 224))
plt.imshow(img)
# 이미지를 array 형태로 변환(학습할 모델의 입력으로 사용하기 위해)
x = image.img_to_array(img)
# 기존 모형에 batch_size=1 추가
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
# 예측
preds = resnet.predict(x)
# 예측 결과 decode_predictions을 통해 반환
print(decode_predictions(preds))
1
2
1/1 [==============================] - 1s 1s/step
[[('n02206856', 'bee', 0.9990982), ('n03530642', 'honeycomb', 0.000561837), ('n02190166', 'fly', 0.00014348973), ('n02727426', 'apiary', 0.0001017911), ('n02219486', 'ant', 5.7517515e-05)]]
## Xception
Inception module을 이용하여 depthwise convolution 적용
기존의 Conv layer에서 얻은 feature map을 각 채널별로 다른 Conv layer에 적용하여 feature map을 얻음
1
from tensorflow.keras.applications.xception import Xception, preprocess_input, decode_predictions
1
2
3
4
xception = Xception(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
xception.summary()
1
!wget -O beaver.jpg https://upload.wikimedia.org/wikipedia/commons/6/6b/American_Beaver.jpg
1
2
3
4
5
6
7
8
9
10
--2023-03-09 14:52:46-- https://upload.wikimedia.org/wikipedia/commons/6/6b/American_Beaver.jpg
Resolving upload.wikimedia.org (upload.wikimedia.org)... 103.102.166.240, 2001:df2:e500:ed1a::2:b
Connecting to upload.wikimedia.org (upload.wikimedia.org)|103.102.166.240|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 186747 (182K) [image/jpeg]
Saving to: ‘beaver.jpg’
beaver.jpg 100%[===================>] 182.37K --.-KB/s in 0.006s
2023-03-09 14:52:46 (28.0 MB/s) - ‘beaver.jpg’ saved [186747/186747]
1
2
3
4
5
6
7
8
9
10
11
12
13
# 다운로드한 beaver.jpg를 terget_size로 줄여줌
# beaver input은 [(None, 299, 299, 3 0)] 크기를 가짐
img = image.load_img('beaver.jpg', target_size=(299, 299))
plt.imshow(img)
# 이미지를 array 형태로 변환(학습할 모델의 입력으로 사용하기 위해)
x = image.img_to_array(img)
# 기존 모형에 batch_size=1 추가
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
# 예측
preds = xception.predict(x)
# 예측 결과 decode_predictions을 통해 반환
print(decode_predictions(preds))
1
2
1/1 [==============================] - 1s 1s/step
[[('n02363005', 'beaver', 0.8280816), ('n02361337', 'marmot', 0.059717532), ('n02493509', 'titi', 0.004413159), ('n02442845', 'mink', 0.0024041226), ('n01883070', 'wombat', 0.0019850638)]]
MobileNet
- 성능보다 모델의 크기 또는 연산 속도 감소
- Depthwise conv와 Pointwise conv 사이에도 batch normalization과 ReLU를 삽입
- Conv layer를 활용한 모델과 정확도는 비슷하면서 계산량은 9배, 파라미터 수는 7배 줄임
1
from tensorflow.keras.applications.mobilenet import MobileNet, preprocess_input, decode_predictions
1
2
3
4
mobilenet = MobileNet(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
mobilenet.summary()
1
!wget -O crane.jpg https://p1.pxfuel.com/preview/42/50/534/europe-channel-crane-harbour-crane-harbour-cranes-cranes-transport.jpg
1
2
3
4
5
6
7
8
9
10
--2023-03-09 14:58:51-- https://p1.pxfuel.com/preview/42/50/534/europe-channel-crane-harbour-crane-harbour-cranes-cranes-transport.jpg
Resolving p1.pxfuel.com (p1.pxfuel.com)... 172.64.201.22, 172.64.200.22, 2606:4700:e6::ac40:c916, ...
Connecting to p1.pxfuel.com (p1.pxfuel.com)|172.64.201.22|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 86911 (85K) [image/jpeg]
Saving to: ‘crane.jpg’
crane.jpg 100%[===================>] 84.87K --.-KB/s in 0.004s
2023-03-09 14:58:52 (19.6 MB/s) - ‘crane.jpg’ saved [86911/86911]
1
2
3
4
5
6
7
8
9
10
11
12
13
# 다운로드한 crane.jpg를 terget_size로 줄여줌
# crane input은 [(None, 224, 224, 3))] 크기를 가짐
img = image.load_img('crane.jpg', target_size=(224, 224))
plt.imshow(img)
# 이미지를 array 형태로 변환(학습할 모델의 입력으로 사용하기 위해)
x = image.img_to_array(img)
# 기존 모형에 batch_size=1 추가
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
# 예측
preds = mobilenet.predict(x)
# 예측 결과 decode_predictions을 통해 반환
print(decode_predictions(preds))
1
2
3
4
5
WARNING:tensorflow:5 out of the last 6 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f7aa7d3c8b0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
1/1 [==============================] - 1s 809ms/step
[[('n03126707', 'crane', 0.95963544), ('n03216828', 'dock', 0.029736752), ('n03240683', 'drilling_platform', 0.0051688235), ('n03344393', 'fireboat', 0.0026515478), ('n04366367', 'suspension_bridge', 0.000502884)]]
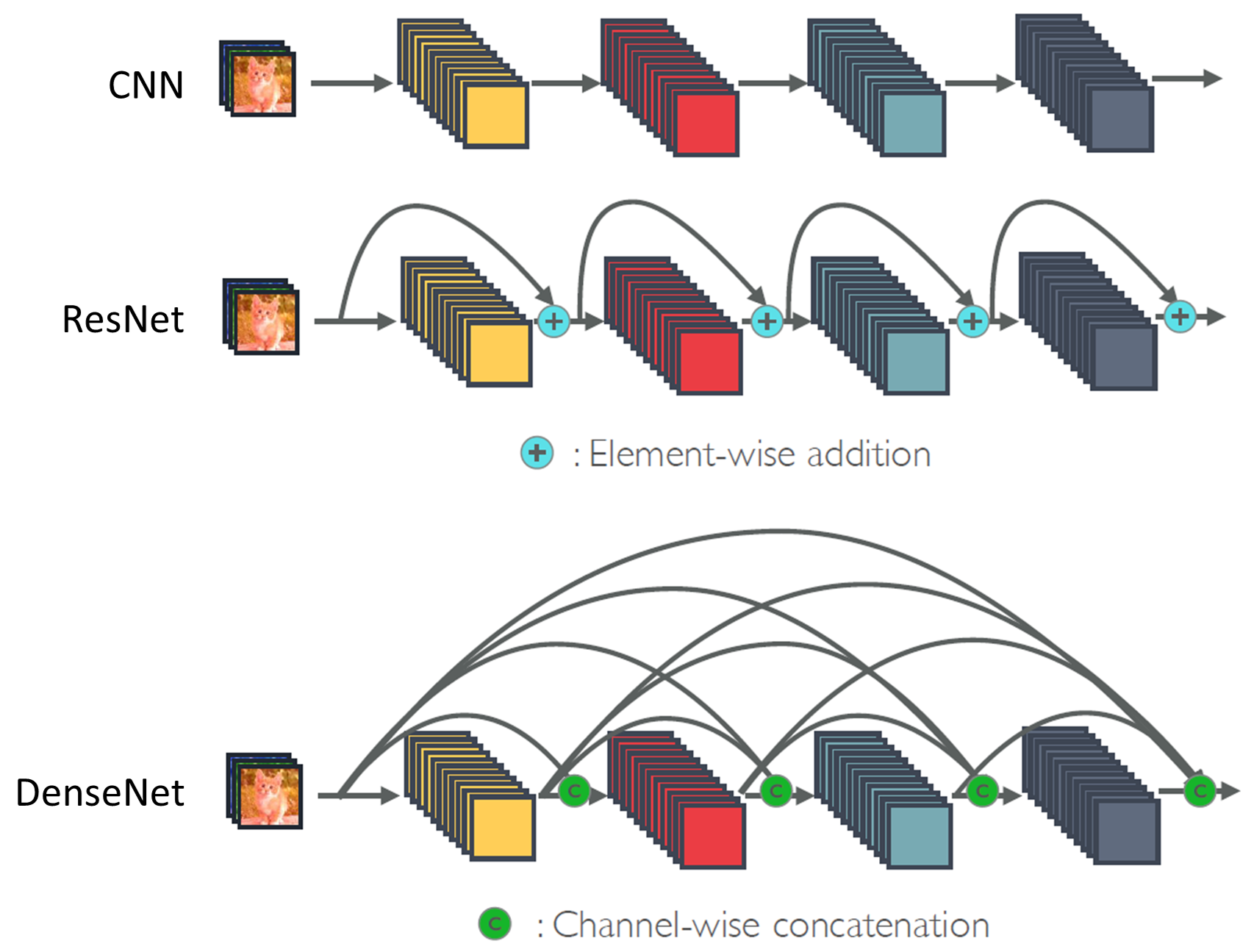
DenseNet
- 각 층은 모든 앞 단계에서 올 수 있는 지름질 연결 구성
- 특징지도의 크기를 줄이기 위해 풀링 연산 적용 필요
- 밀집 블록(dense block)과 전이층(transition layer)으로 구성
- 전이층 : 1x1 컨볼루션과 평균값 풀링(APool)으로 구성
1
from tensorflow.keras.applications.densenet import DenseNet201, preprocess_input, decode_predictions
1
2
3
4
densenet = DenseNet201(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
densenet.summary()
1
!wget -O zebra.jpg https://upload.wikimedia.org/wikipedia/commons/f/f0/Zebra_standing_alone_crop.jpg
1
2
3
4
5
6
7
8
9
10
--2023-03-09 15:03:49-- https://upload.wikimedia.org/wikipedia/commons/f/f0/Zebra_standing_alone_crop.jpg
Resolving upload.wikimedia.org (upload.wikimedia.org)... 103.102.166.240, 2001:df2:e500:ed1a::2:b
Connecting to upload.wikimedia.org (upload.wikimedia.org)|103.102.166.240|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 188036 (184K) [image/jpeg]
Saving to: ‘zebra.jpg’
zebra.jpg 100%[===================>] 183.63K --.-KB/s in 0.007s
2023-03-09 15:03:49 (24.8 MB/s) - ‘zebra.jpg’ saved [188036/188036]
1
2
3
4
5
6
7
8
9
10
11
12
13
# 다운로드한 zebra.jpg를 terget_size로 줄여줌
# zebra input은 [(None, 224, 224, 3 0)] 크기를 가짐
img = image.load_img('zebra.jpg', target_size=(224, 224))
plt.imshow(img)
# 이미지를 array 형태로 변환(학습할 모델의 입력으로 사용하기 위해)
x = image.img_to_array(img)
# 기존 모형에 batch_size=1 추가
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
# 예측
preds = densenet.predict(x)
# 예측 결과 decode_predictions을 통해 반환
print(decode_predictions(preds))
1
2
3
4
5
WARNING:tensorflow:6 out of the last 7 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f7bb90f8700> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
1/1 [==============================] - 4s 4s/step
[[('n02391049', 'zebra', 0.9312889), ('n01518878', 'ostrich', 0.019832587), ('n02423022', 'gazelle', 0.011593062), ('n02397096', 'warthog', 0.0046255025), ('n02422106', 'hartebeest', 0.003152003)]]
NasNet
- 신경망 구조를 사람이 설계하지 않고, complete search를 통해 자동으로 구조를 찾아냄
- 네트워크를 구성하는 layer를 하나씩 탐색하는 NAS 방법 대신, NasNet은 Convolution cell 단위를 먼저 추정하고, 이들을 조합하여 전체 네트워크 구성
- 성능은 높지만, 파라미터 수와 연산량은 절반 정도로 감소
1
from tensorflow.keras.applications.nasnet import NASNetLarge, preprocess_input, decode_predictions
1
2
3
4
nasnet = NASNetLarge(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
nasnet.summary()
1
!wget -O notebook.jpg https://cdn.pixabay.com/photo/2016/07/11/03/35/macbook-1508998_1280.jpg
1
2
3
4
5
6
7
8
9
10
--2023-03-09 15:07:53-- https://cdn.pixabay.com/photo/2016/07/11/03/35/macbook-1508998_1280.jpg
Resolving cdn.pixabay.com (cdn.pixabay.com)... 104.18.14.16, 104.18.15.16, 2606:4700::6812:f10, ...
Connecting to cdn.pixabay.com (cdn.pixabay.com)|104.18.14.16|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 270631 (264K) [binary/octet-stream]
Saving to: ‘notebook.jpg’
notebook.jpg 100%[===================>] 264.29K --.-KB/s in 0.01s
2023-03-09 15:07:54 (20.4 MB/s) - ‘notebook.jpg’ saved [270631/270631]
1
2
3
4
5
6
7
8
9
10
11
12
13
# 다운로드한 notebook.jpg를 terget_size로 줄여줌
# notebook input은 [(None, 331, 331, 3 0)] 크기를 가짐
img = image.load_img('notebook.jpg', target_size=(331, 331))
plt.imshow(img)
# 이미지를 array 형태로 변환(학습할 모델의 입력으로 사용하기 위해)
x = image.img_to_array(img)
# 기존 모형에 batch_size=1 추가
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
# 예측
preds = nasnet.predict(x)
# 예측 결과 decode_predictions을 통해 반환
print(decode_predictions(preds))
1
2
1/1 [==============================] - 6s 6s/step
[[('n03832673', 'notebook', 0.79294485), ('n03642806', 'laptop', 0.048423648), ('n04264628', 'space_bar', 0.034534946), ('n03085013', 'computer_keyboard', 0.020163987), ('n03777754', 'modem', 0.011375744)]]
EfficientNet
- EfficientNetB0인 작은 모델에서 주어진 Task에 최적화된 구조로 수정해나가는 형태
- 복잡한 Task에 맞춰 모델의 Capacity를 늘리기 위해 Wide Scaling, Deep Scaling, 그리고 Resolution Scaling을 사용
- EfficientNet은 Wide, Deep, Resolution을 함께 고려하는 Compound Scaling을 사용
1
from tensorflow.keras.applications.efficientnet import EfficientNetB1, preprocess_input, decode_predictions
1
2
3
4
eff = EfficientNetB1(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None, classes=1000)
eff.summary()
1
!wget -O plane.jpg https://upload.wikimedia.org/wikipedia/commons/1/12/Plane-in-flight.jpg
1
2
3
4
5
6
7
8
9
10
--2023-03-09 15:11:13-- https://upload.wikimedia.org/wikipedia/commons/1/12/Plane-in-flight.jpg
Resolving upload.wikimedia.org (upload.wikimedia.org)... 103.102.166.240, 2001:df2:e500:ed1a::2:b
Connecting to upload.wikimedia.org (upload.wikimedia.org)|103.102.166.240|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 487351 (476K) [image/jpeg]
Saving to: ‘plane.jpg’
plane.jpg 100%[===================>] 475.93K --.-KB/s in 0.02s
2023-03-09 15:11:14 (29.2 MB/s) - ‘plane.jpg’ saved [487351/487351]
1
2
3
4
5
6
7
8
9
10
11
12
13
# 다운로드한 plane.jpg를 terget_size로 줄여줌
# plane input은 [(None, 240, 240, 3 0)] 크기를 가짐
img = image.load_img('plane.jpg', target_size=(240, 240))
plt.imshow(img)
# 이미지를 array 형태로 변환(학습할 모델의 입력으로 사용하기 위해)
x = image.img_to_array(img)
# 기존 모형에 batch_size=1 추가
x = x.reshape((1, x.shape[0], x.shape[1], x.shape[2]))
x = preprocess_input(x)
# 예측
preds = eff.predict(x)
# 예측 결과 decode_predictions을 통해 반환
print(decode_predictions(preds))
1
2
1/1 [==============================] - 2s 2s/step
[[('n02690373', 'airliner', 0.75877386), ('n04592741', 'wing', 0.100808546), ('n04552348', 'warplane', 0.08239551), ('n04266014', 'space_shuttle', 0.0063430285), ('n02692877', 'airship', 0.00088727544)]]